What is a Stochastic Learning Algorithm?
Stochastic learning algorithms are a broad family of algorithms that process a large dataset by sequential processing of random samples of the dataset. Since their per-iteration computation cost is independent of the overall size of the dataset, stochastic algorithms can be very efficient in the analysis of large-scale data. Examples of stochastic algorithms include:
- Stochastic Gradient Descent (SGD)
- Stochastic Dual Coordinate Ascent (SDCA)
- Markov Chain Monte Carlo (MCMC)
- Gibbs Sampling
- Stochastic Variational Inference
- Expectation Propagation
What is Splash?
Stochastic learning algorithms are generally defined as sequential procedures and as such they can be difficult to parallelize. Splash is a general framework for parallelizing stochastic learning algorithms on multi-node clusters. You can develop a stochastic algorithm using the Splash programming interface without worrying about issues of distributed computing. The parallelization is automatic and it is communication efficient. Splash is built on Scala and Apache Spark, so that you can employ it to process Resilient Distributed Datasets (RDD).
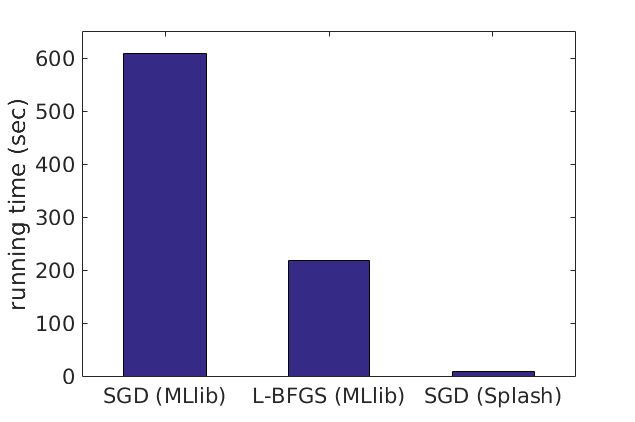
On large-scale datasets, Splash can be substantially faster than existing data analytics packages built on Apache Spark. For example, to fit a 10-class logistic regression model on the mnist8m dataset, stochastic gradient descent (SGD) implemented with Splash is 25x faster than MLlib’s L-BFGS and 75x faster than MLlib’s mini-batch SGD for achieving the same value of the loss function. All algorithms run on a 64-core cluster.
Read the Quick Start guide to start building your own stochastic algorithm, read our paper to learn more about what is under the hood, and view the source code here.